repeatOnLifecycle, launchWhen...에 대해서
08 Sep, 2022
최근에 저는 LiveData에서 StateFlow로 넘어가면서 항상 코드에 다음과 같이 작성해주었습니다.
viewLifecycleOwner.lifecycleScope.launch {
viewLifecycleOwner.repeatOnLifecycle(Lifecycle.State.STARTED) {
viewModel.someDataFlow.collect {
// Process item
}
}
}
그런데 어느 정도는 알지고 있었지만, 제대로 알지 못해 더 자세하게 알고 싶어서 포스팅하게 됐습니다.
먼저 lifecycleScope는 Android Developer를 보면, LifeCycle이 DESTROYED일 때 장기적인 job을 자동으로 취소해준다고 되어있습니다. 그런데 취소해주는 것과 별개로, 특정 상황에서 시작해야 할 때는 어떻게 할까요? 또한 작업을 특정 Lifecycle의 State에서 반복하고 싶다면 어떻게 해야 할까요?
FragmentTranscation을 실행하려면 Lifecycle이 적어도 STARTED 상태가 되어야 하는데, 이러한 상황을 위해서 LaunchWhenX~ 함수가 존재합니다! 예를 들어 launchWhenStarted를 사용하여 CoroutineScope를 만들게 되면, STARTED의 생명주기에 맞추어 실행되고, 정지됩니다.
launchWhenStarted의 내부 함수를 보겠습니다!

내부의 whenStarted는 아래의 함수로 만들어져있는데, coroutineScope의 block을 LifecycleState가 STARTED일 때 시작, 취소해주는 함수인 것 같네요!

또 한 번 내부를 들어가 보겠습니다.
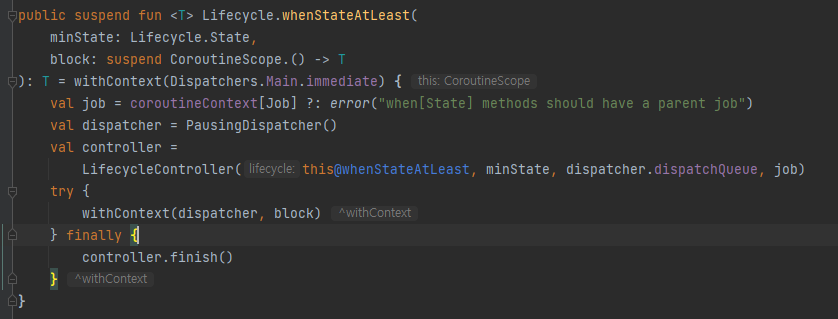
내부에서 dispatcher와 job을 지정해주고, withContext() 메소드를 실행시켜줍니다. withContext() 내부를 보면, 다음과 같습니다.
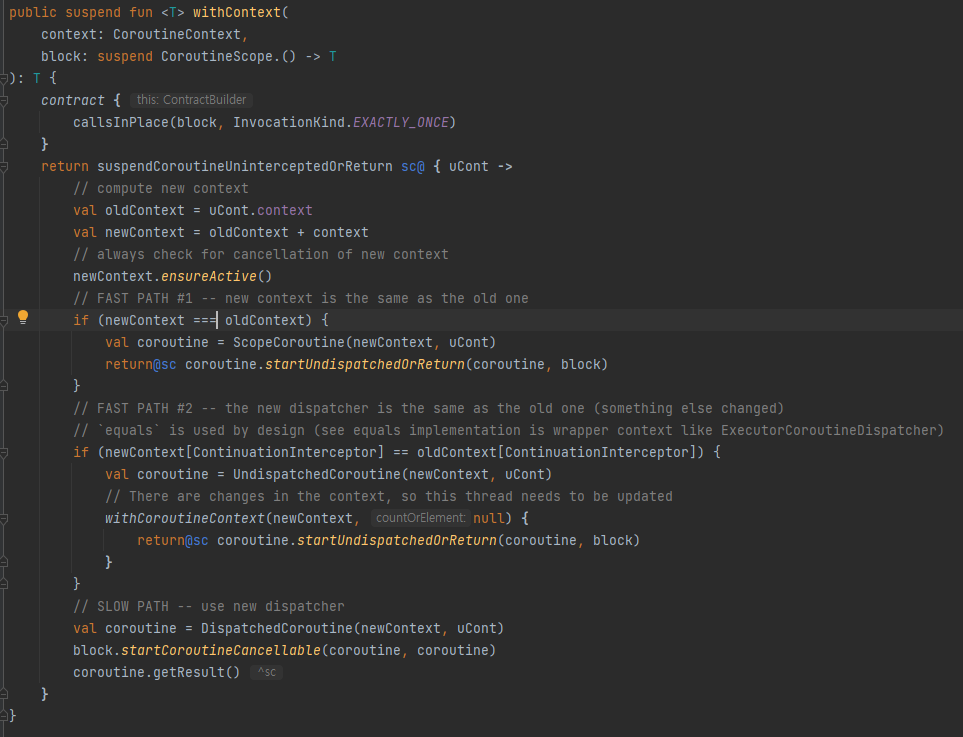
내용이 길지만, 인자로 받아온 context를 newContext에 넣고, 해당 context가 유효하게끔 바꿉니다. (해당 함수를 통해 CancellationException을 지나칩니다)
그리고, 몇가지 분기 처리에 의해 나뉘지만 결국은 newContext와 uCont를 가지고 코루틴을 실행합니다. (여기 uCont는 설명이 길어져 쓰지 않지만, 부모 코루틴이라고 생각하시면 될 것 같습니다! 참조
이야기가 길어졌지만, 해당 lifecycleScope.launchX을 관리하는 부분은 아래와 같습니다.
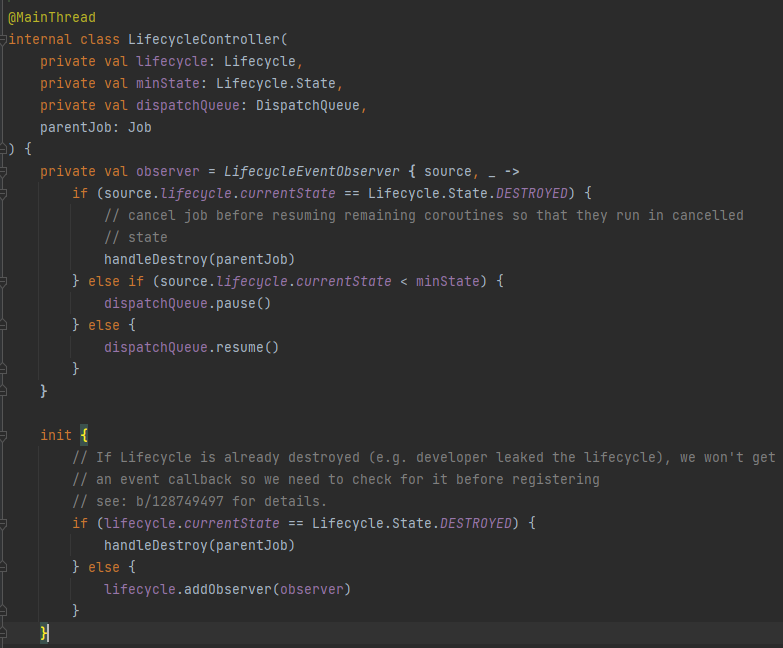
observer를 만들어서 지정한 State에서만 resume()하고, 아닌경우 pause()하도록 이루어져있습니다! 그리고 STATE가 DESTROYED인 경우 handleDestroy()를 실행해 멈추어 줍니다.
그런데 이러한 launch() 함수는 해당 activity, fragment의 lifecycle에서 단 한번만 실행된다는 단점이 있습니다.
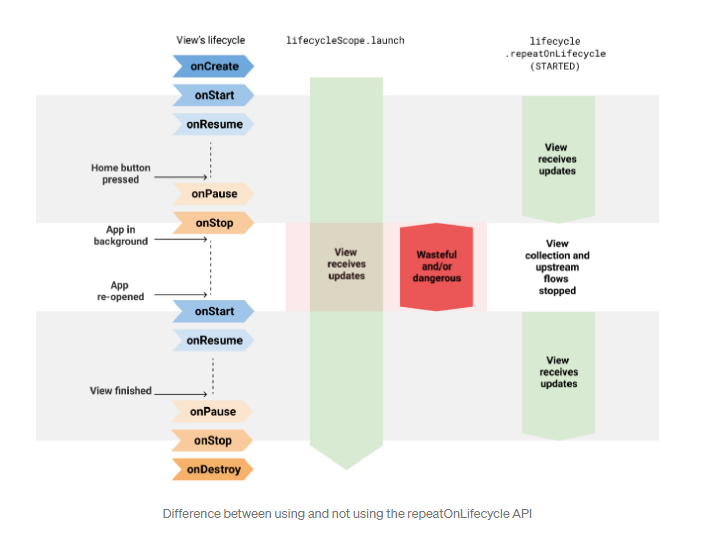
Lifecylce의 특정 상태에 있을 때 코드 블록의 실행을 다시 시작하고, 다른 상태일 때 자동으로 정지하고싶을 수도 있습니다. 이러한 작업을 repeatOnLifecycle이 도와줍니다!
LiveData는 안드로이드에 특화된 Data type으로 값 스스로 안드로이드의 생명주기를 알지만, Flow의 경우 안드로이드 라이브러리가 아닌, Kotlin의 라이브러리이기 때문에 안드로이드의 생명주기를 알지 못합니다. 그래서 개발자가 직접 데이터를 다루어주어야 하는데, 이를 돕는게 바로 repeatOnLifecycle입니다.
위의 코드에서는 Lifecycle.State의 STARTED, 즉 onStart, onResume, onStop 에서만 작동하며 onStart에서 flow를 수집, onStop에서 flow 수집을 멈추게 됩니다.
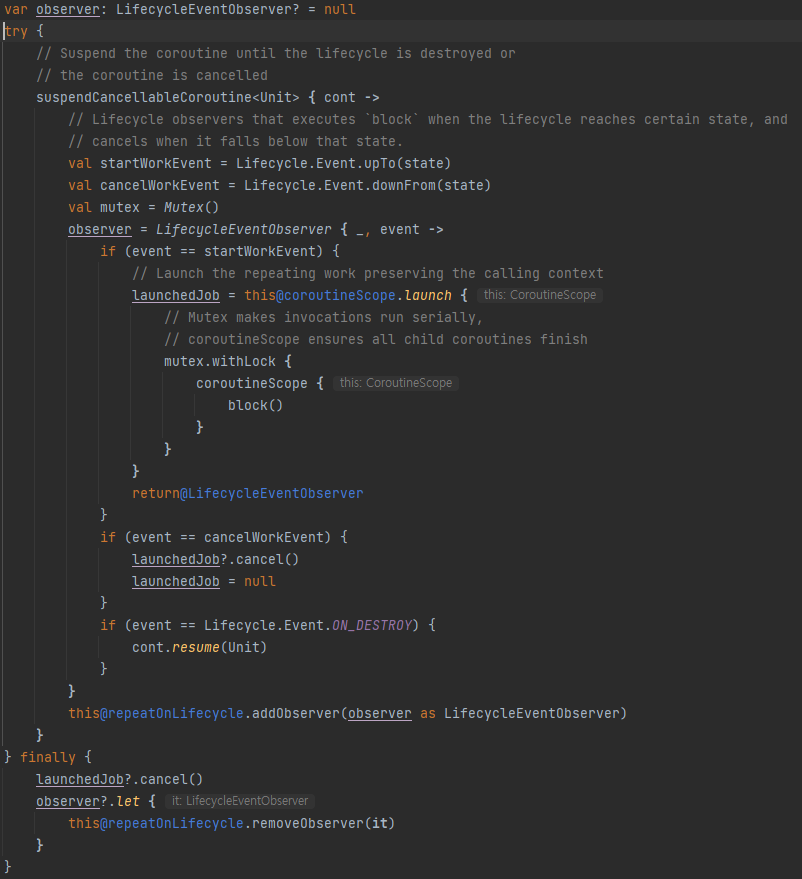 repeatOnLifecycle의 내부 함수입니다.
repeatOnLifecycle의 내부 함수입니다.
짧게 요약하자면, 옵저버를 만들고, startWorkEvent와 cancelWorkEvent를 생성하여, 옵저버를 통해 해당 Lifecycle에 도달하면, 코루틴 job을 생성하고, 취소하는 작업을 반복합니다. 또한 try finally문으로 try문의 suspendCancellableCoroutine이 끝날 때 job을 cancel해주고, observer를 제거해줍니다.
즉, 실제로 코루틴을 멈추고, 실행하는 것이 아닌, 각각의 실제 STATE 상태에서 job을 생성하고, cancel해주는 작업을 반복합니다.
결론은, 위의 lifecycleScope.launch와 repeatOnLifecycle을 같이 써서, 설정한 생명주기에 부합하는 경우에만 코루틴을 실행시켜주고, 그 외의 상태에서는 값을 collect 하는 것을 정지 상태로 두게끔 도와주는 것입니다. LiveData에서 자동으로 해주던 것을, 조금 더 귀찮지만 한줄 더 써서 비슷한 기능을 하게끔 돕는다고 생각하면 쉽겠네요!!
이러한 기능(repeatOnLifecycle)을 귀찮지만 꼭 사용해주어야 합니다. LiveData에서는 해주던 기능을 Flow에서 적용해주지 않는다면, 앱이 백그라운드로 갔을 때, 멈추지 않아 리소스를 낭비하기 때문입니다. 만약 사용하지 않고 lifecycleScope만 적용해줄 경우, 백그라운드에 있어 화면을 표시하지 않아도 계속해서 수집하고 있게 됩니다. 왜냐면 DESTROYED 상태가 아니기 때문이죠!
직접 onStart에서 시작, onStop에서 취소해주는 것보다는, repeatOnLifecycle로 간편하게 사용하는 편이 더좋겠죠??
추가적으로 Fragment에서 사용할때는 일반 lifecycleScope보다는 viewLifecycleOwner를 사용해야합니다. 아래 간단한 표로 확인 해보세요!!!! 왼쪽이 lifecylceScope.launch만 사용할 때, 오른쪽이 repeatOnLifecycle을 적용했을 때 입니다.
내용이 길었지만, LiveData에서 StateFlow로 넘어가기 위해서 알고 사용하면 좋을 LifecycleScope.launch와, repeatOnLifeCycle에 대해서 알아보았습니다!


