Reactive - 변환 연산자
20 Jan, 2021
Reactive 변환 연산자
리액티브 연산자
- 생성연산자: Observable로 데이터 흐름을 만든다
- 변환연산자, 필터 연산자: 데이터 흐름을 원하는 방식으로 변형
- 결합연산자: 1개의 Observer이 아니라 여러 개의 Observable을 조합할 수 있도록 해준다
| 연산자 종류 | 연산자 함수 |
|---|---|
| 생성 연산자 | just(), fromXXX(), create(), interval(), range(), timer(), intervalRange(), defer(), repeat() |
| 변환 연산자 | map(), flatMap(), concatMap(), switchMap), groupBy(), scan(), buffer(), window() |
| 필터 연산자 | filter(), take(), skip(), distinct() |
| 결합 연산자 | zip(), combineLatest(), Merge(), concat() |
| 조건 연산자 | amb(), takeUntil(), skipUntil(), all() |
| 에러 처리 연산자 | onErrorReturn(), onErrorResumeNext(), retry(), retryUntil() |
| 기타 연산자 | subscribe(), subscribeOn(), observeOn(), reduce(), count() |
변환 연산자
변환연산자는 데이터 흐름을 원하는 대로 변형할 수 있습니다.
flatMap과 같은 계열인 concatMap(), switchMap() 함수에 대해 알아보고 reduce와 유사한 scan() 함수, 그리고 groupBy() 함수에 대해 살펴보겠습니다
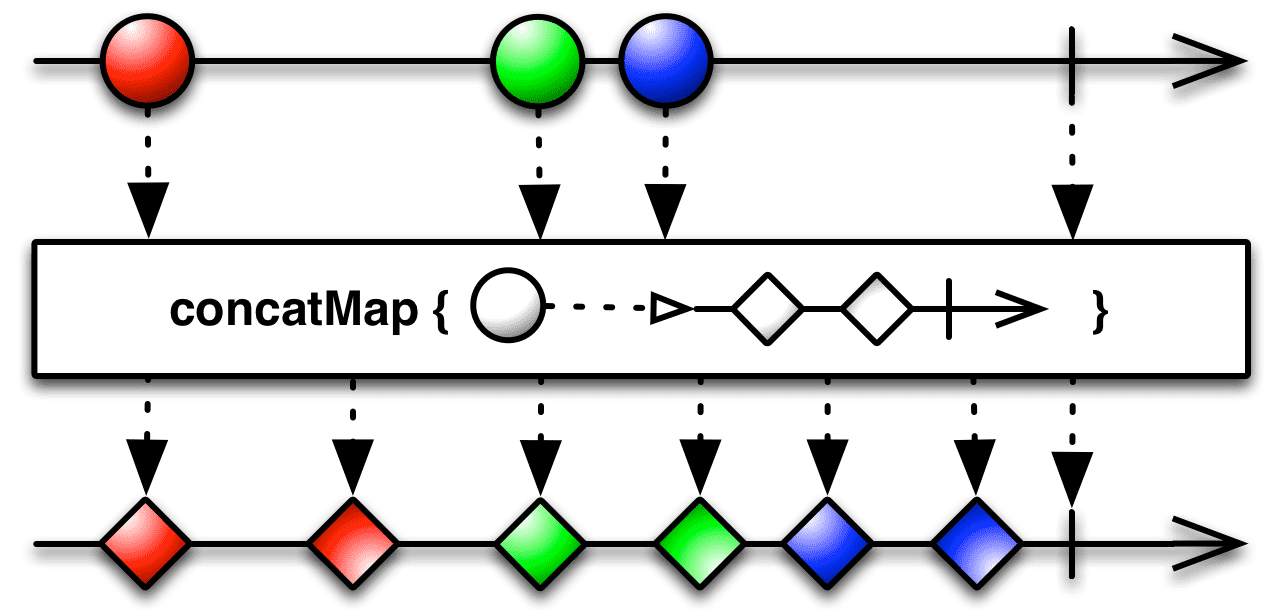
1. concatMap() 함수
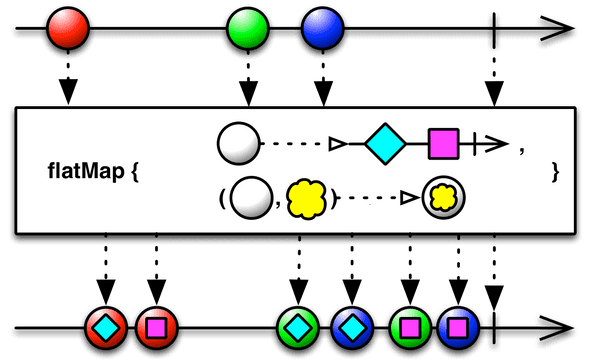
concatMap() 함수는 flatMap()함수와 매우 비슷합니다. flatMap() 는 먼저 들어온 데이터를 처리하는 도중에 새로운 데이터가 들어오면 나중에 들어온 데이터의 처리 결과가 먼저 출력될 수도 있습니다. 이를 인터리빙 interleaving(끼어들기) 라고 합니다. 하지만 concatMap() 함수는 먼저 들어온 데이터 순서대로 처리해서 결과를 낼 수 있도록 보장해줍니다.
flatMap 마블 다이어그램
예시 코드
CommonUtils.exampleStart(); //시간을 측정하기 위해 호출 String[] balls = {"1", "2", "3"}; Observable<String> source = Observable.interval(100L, TimeUnit.MILLISECONDS) .map(Long::intValue) .map(idx -> balls[idx]) .take(3) .flatMap( ball -> Observable.interval(200L, TimeUnit.MILLISECONDS) .map(notUsed -> ball + "<>") .take(2)); source.subscribe(Log::it); CommonUtils.sleep(2000); CommonUtils.exampleComplete();결과
RxComputationThreadPool-6 | 358 | value = 1<> RxComputationThreadPool-7 | 459 | value = 3<> RxComputationThreadPool-6 | 559 | value = 1<> RxComputationThreadPool-6 | 559 | value = 5<> RxComputationThreadPool-7 | 659 | value = 3<> RxComputationThreadPool-8 | 755 | value = 5<>
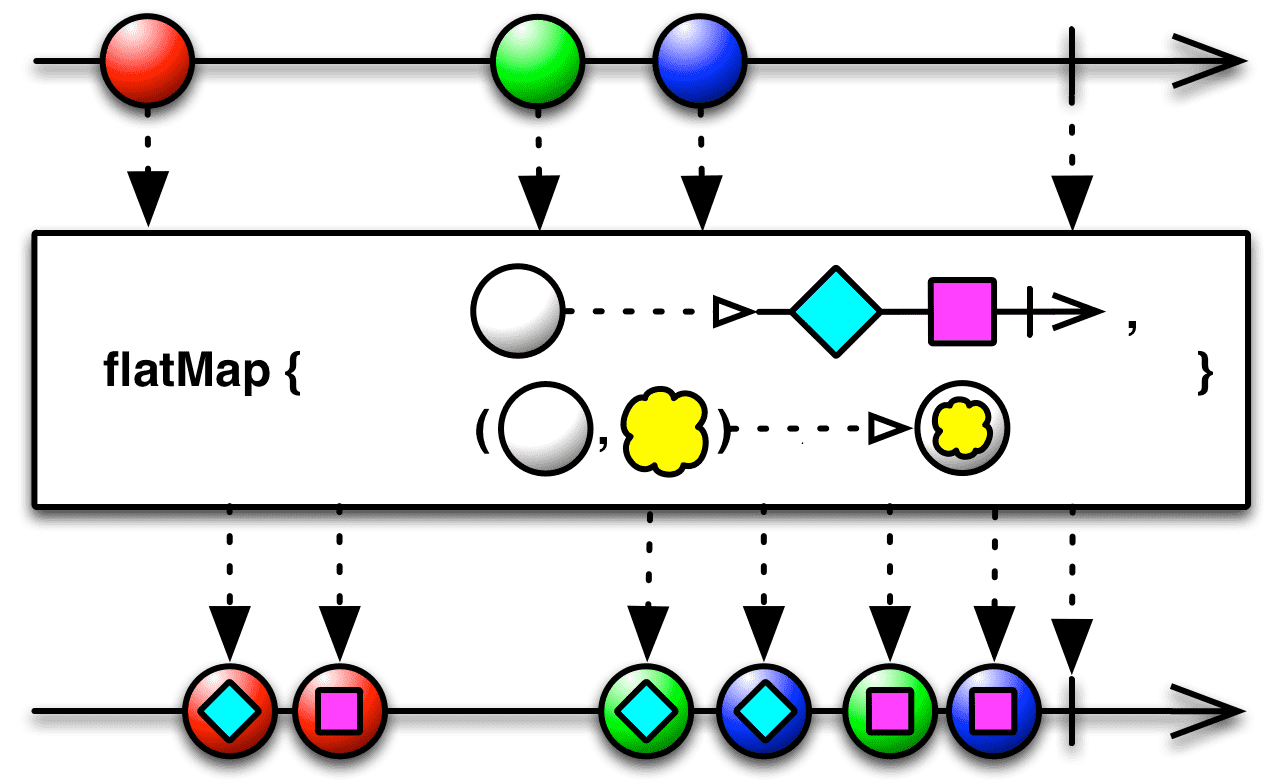
concatMap 다이어그램
concatMap은 순서를 보장하기 위해 flatMap의 실행 시간에 비해 추가시간이 필요할 수 있습니다.
예시코드
CommonUtils.exampleStart(); //시간을 측정하기 위해 호출
String[] balls = {RED, GREEN, BLUE}; //1, 3, 5
Observable<String> source = Observable.interval(100L, TimeUnit.MILLISECONDS)
.map(Long::intValue)
.map(idx -> balls[idx])
.take(balls.length)
.concatMap(
ball -> Observable.interval(200L, TimeUnit.MILLISECONDS)
.map(notUsed -> ball + "<>")
.take(2)); //2개의 다이아몬드
source.subscribe(Log::it);
CommonUtils.sleep(2000);
CommonUtils.exampleComplete();결과
RxComputationThreadPool-2 | 442 | value = 1<>
RxComputationThreadPool-2 | 639 | value = 1<>
RxComputationThreadPool-3 | 844 | value = 3<>
RxComputationThreadPool-3 | 1044 | value = 3<>
RxComputationThreadPool-4 | 1248 | value = 5<>
RxComputationThreadPool-4 | 1448 | value = 5<>2. switchMap() 함수
concatMap() 함수가 인터리빙이 발생할 수 있는 상황에서 동작의 순서를 보장해준다면 switchMap() 함수는 순서를 보장하기 위해 기존에 진행중이던 동작을 바로 중단합니다. 여러개의 값이 발행되었을 때 마지막에 들어온 값만 처리하고 싶을 때 사용합니다. 중간에 끊기더라도 마지막 데이터의 처리는 보장하기 때문이죠.
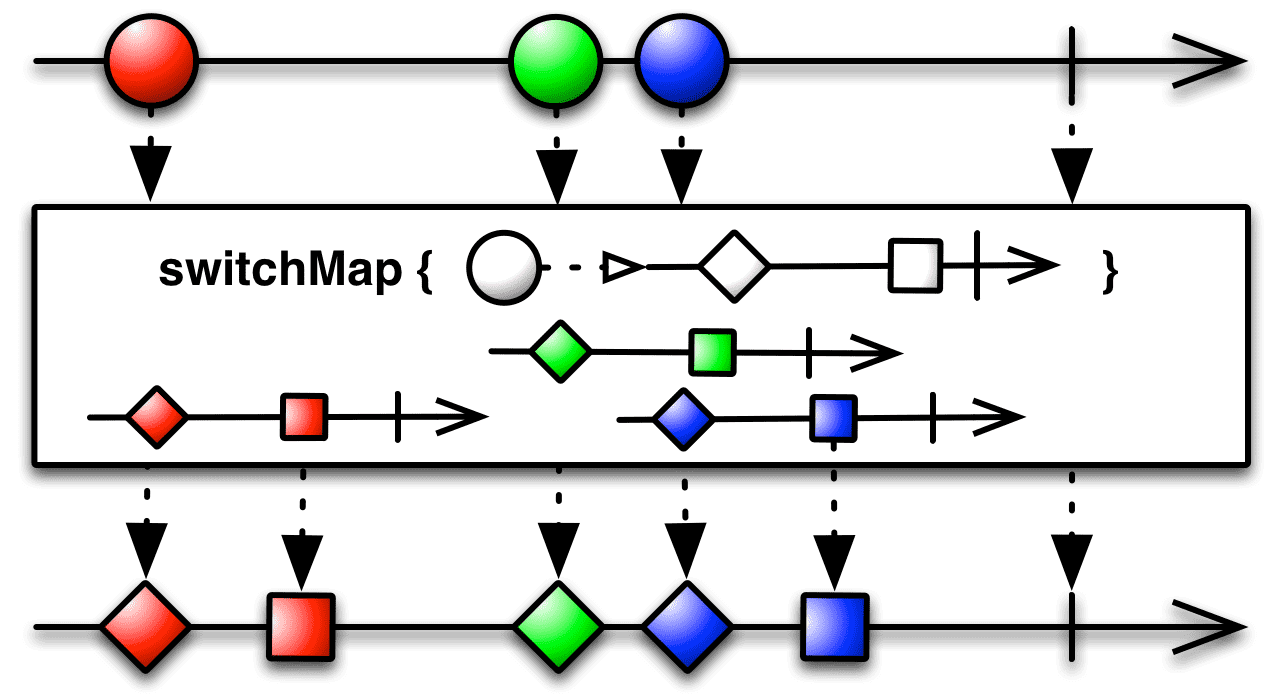
예시코드
CommonUtils.exampleStart(); //시간을 측정하기 위해 호출
String[] balls = {"1", "2", "3"};
Observable<String> source = Observable.interval(100L, TimeUnit.MILLISECONDS)
.map(Long::intValue)
.map(idx -> balls[idx])
.take(balls.length)
.switchMap(
ball -> Observable.interval(200L, TimeUnit.MILLISECONDS)
.map(notUsed -> ball + "<>")
.take(2));
source.subscribe(Log::it);
CommonUtils.sleep(2000);
CommonUtils.exampleComplete();결과
RxComputationThreadPool-4 | 665 | value = 5<>
RxComputationThreadPool-4 | 865 | value = 5<>호출 부분을 제외하면 concatMap() 함수와 같지만 결과는 매우 다릅니다. doOnNext() 를 넣어 중간 결과를 확인해봅니다.
CommonUtils.exampleStart(); //시간을 측정하기 위해 호출
String[] balls = {"1", "2", "3"};
Observable<String> source = Observable.interval(100L, TimeUnit.MILLISECONDS)
.map(Long::intValue)
.map(idx -> balls[idx])
.take(balls.length)
.doOnNext(Log::dt) //중간결과 확인용
.switchMap(
ball -> Observable.interval(200L, TimeUnit.MILLISECONDS)
.map(noValue -> ball + "<>")
.take(2));
source.subscribe(Log::it);
CommonUtils.sleep(2000);
CommonUtils.exampleComplete();결과
RxComputationThreadPool-1 | 228 | debug = 1
RxComputationThreadPool-1 | 324 | debug = 3
RxComputationThreadPool-1 | 428 | debug = 5
RxComputationThreadPool-4 | 632 | value = 5<>
RxComputationThreadPool-4 | 830 | value = 5<>위 결과를 보면 두가지를 알 수 있습니다.
첫 번째로 Observable은 데이터를 발행하는 스레드와 그 값을 전달하는 스레드를 다르게 사용하고 있습니다.
concatMap() , flatMap(), switchMap() 함수 활용 예의 실행 결과서 본 스레드는 1번 스레드 없이 2,3,4번만 발행했습니다. 그 이유는 1번스레드는 값을 발행하는데 사용했기 때문입니다. 1번 스레드에서 값을 발행하고 2,3,4번 스레드를 통해서 구독자에게 값을 전달한 것 입니다.
두 번째로 5<> 만 출력했다는 점입니다. <> 는 200ms 간격으로 발행하기 때문에 1 <> 이 발행되기 전에 5<>이 발행되어 버렷습니다. 그래서 중간에 있는 3<>의 발행이 취소되고 마지막 5를 이용한 5<>만 두 번 출력합니다.
switchMap() 함수는 센서 등의 값을 얻어와 동적으로 처리하는 경우에 유용합니다. 중간값보다는 최종적인 값으로 결과를 처리하는 경우가 많기 때문입니다. flatMap() 으로 매번 새 결과를 확인하기 보다는 switchMap() 으로 쉽게 확인이 가능합니다.
3. groupBy() 함수
groupBy() 함수는 어떤 기준(keySelector)으로 단일 Observable을 여러개로 이루어진 Observable 그룹으로 만듭니다.
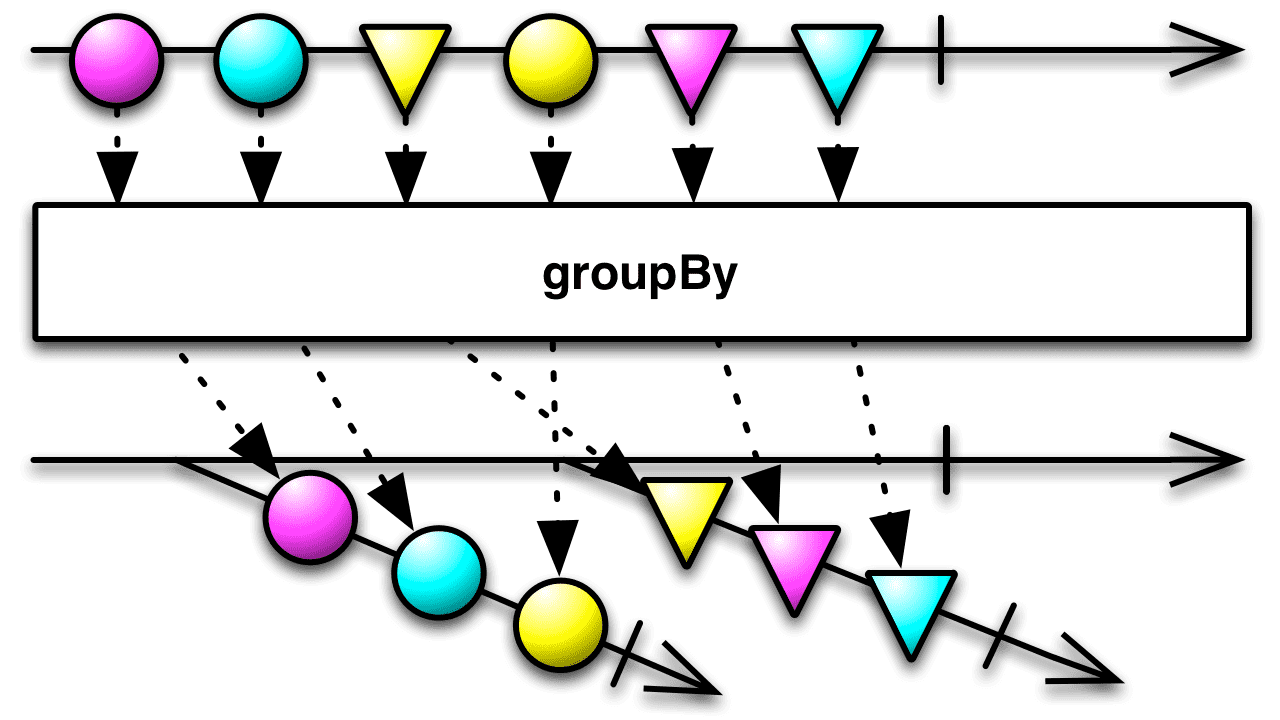
어떤 기준으로 Observable 각각을 여러 개 Observable의 그룹으로 구분한다고 생각 하면 되며 아래 예시 코드에서 자세히 살펴봅시다.
String[] objs = {"6", "4", "2-T", "2", "6-T","4-T"};
Observable<GroupedObservable<String, String>> source =
Observable.fromArray(objs)
.groupBy(Shape::getShape);
source.subscribe(obj -> {
obj.filter(val -> obj.getKey().equals(Shape.BALL))
.subscribe(val ->
System.out.println("GROUP:" + obj.getKey() + "\t Value:" + val));
});
CommonUtils.exampleComplete();GroupedObservable 클래스는 Observable과 동일하지만 getKey() 라는 메서드를 제공하여 구분된 그룹을 알 수있게 해줍니다. source 는 objs[] 배열에서 입력 데이터를 가져오고 그룹을 구별하는 방법은 Common util 안에 getShape 라는 메서드로 구분합니다. source.subscribe()에 전달하는 obj는 GroupedObservable 객체로 그룹별 1개씩 생성되기 때문에 생성된 obj 별로 subscribe() 함수를 호출해야 하고 val 은 그룹 안에서 각 Observable이 발행한 데이터를 의미합니다.
결과
GROUP:BALL Value:6
GROUP:BALL Value:4
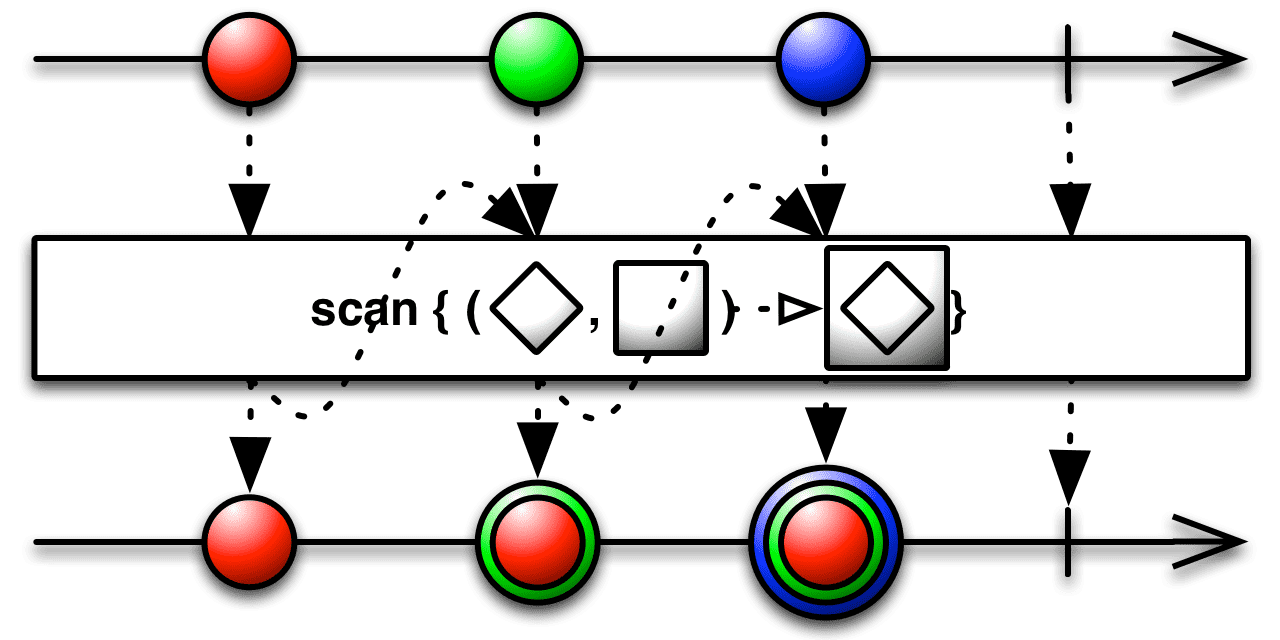
GROUP:BALL Value:24. scan() 함수
scan() 함수는 reduce() 함수와 비슷합니다. reduce() 함수는 Observable 에서 모든 데이터가 입력된 후 그것을 종합하여 마지막 1개의 데이터만 구독자에게 발행했지만 scan() 함수는 실행할 때마다 입력값에 맞는 중간 결과 및 최종 결과를 구독자에게 발행합니다.
reference


